“Ideally, we want news feed to show all the posts people want to see in the order they want to read them.”
— Facebook
What Are Algorithmic Values?
From our perspective, the purpose of a recommender algorithm is simply to give us the content or products we really want to see. There is a problem right off the bat. We don’t know what content or products we really want to see. If we did, we wouldn’t need a recommender engine! Next, a type of algorithm called, “collaborative filtering” steps onto the scene. If you’ve viewed all the Judd Apatow (Director of Knocked Up) movies, the algorithm could observe that other Apatow fans have also ordered Anchorman. Out pops the recommendation. What? You’ve already seen Anchorman five times on a separate site, or at a friend’s house? The recommendation is just noise.
Here is the thing, though: It costs the site very little, on the margin, to deliver a recommendation with no value. Any increase in incremental clicks from populating your recommendations is gravy for them. This creates a fundamental imbalance: Your time is more valuable to you than it is to the algorithm. Any improvement in clicks or time spent on the site benefits their designer’s bottom line, even if it doesn’t quite benefit you as much. Netflix gingerly steps around this issue: “We are not recommending [a movie] because it suits our business needs, but because it matches the information we have from you.” Hmmm… it might be more accurate to say that using the information they have from you serves their business needs.
What’s In It For Us?
Well, watching the TV news, for instance, or searching through IMDB for a movie, or asking a friend, they also take time. Either way we have to wade through useless information. Perhaps the Facebook News Feed algorithm is a big improvement. Or maybe it isn’t, but we are on Facebook a lot anyway, so why not. We learn to adjust to recommendation noise over time, perhaps mentally filtering out irrelevant stories or obtrusive ads as we, say, read through our Facebook news feed. This last dynamic is important. “Digital inertia” keeps us walking down the path that the sites we depend on have laid out for us. Once we swipe through online dating profiles at a mind-numbing pace, well, we just get used to it. This is “just the way things are.” In a sense, we are trapped by this new worldview. Whatever values we had before, now we have a set that benefit the algorithm provider. As our accompanying interview with Spritzr dating app CEO Manshu Argawal describes, this shift in values may not be to our individual, or especially, our collective benefit. After all, when we enter the portal that we expect will connect us to a whole world of possibilities, what we’re really hoping is that it’ll be the scaled up equivalent of taking a walk down a friendly street we’ve never been down.
You might not think that algorithms are all that invasive. After all, the Internet is huge and full of noise (and sometimes, rife with dumb). It’s a self-organizing map, a web of connections whose pathways are forged by whatever pilgrims made them first. Just like ants find scent trails by detecting the pheromones of the hungry ants who traveled before them, or the way neurons that fire together wire together, we leave a trail when we go from one site to the next. That trail is recorded by an algorithm that assumes we liked our route. And so it recommends future itineraries based on what we’ve already seen before. That’s great — better than if it hadn’t paid attention at all, right? But what happens when the recommending algorithm knows you too well? Perhaps one morning you open your news feed and it anticipates your interests so accurately that, to your dismay, the app that once made you laugh into your morning coffee or forget all about your boring train ride no longer has anything interesting to say? There’s almost nowhere we go that we don’t take our mobile device with us. There are no more closed doors. It’s seen our embarrassing searches and medical questions, it knows all the dumb vines we liked. We can’t go back to first dates and first impressions. It thinks it knows who we are. Will we fall out of love?
Mystery, discovery, surprise. These are on the mind of Jarno Koponen, a network science enthusiast, designer and previously, co-founder of the app Random, an experimental discovery engine. It’s guys like this you might expect to design something like the frighteningly capable and caring AI companion in the movie Her. Koponen seems to understand that the Internet, as a complex network, is in a sense a wild frontier that fluctuates between signal and noise, order and chaos. Too much chaos and links are weak, and you’re on your own in the search for relevant information. Too much order and you could get stuck on Main Street, your preferences over-defined by algorithms that attempt to guide you by making assumptions about your activity and comparing you to others. Learning algorithms are humanity’s early attempt to curate culture and relevance just like we have done on every other frontier. But these algorithms now need to learn boundaries, need to learn when we need some space to take a walk alone and be surprised.
And so dawns the age of the discovery engine. There are lots of ways to invent one, but no one’s yet done it comprehensively.
Koponen proposes the creation of personal algorithms — an ‘algorithmic angel’ if you will, which would give us better visibility into the kinds of things that affect what information is curated for us. Today that information is mostly kept safe and proprietary by the designers of the interfaces we use. For instance when you like or comment on a post in Facebook, you don’t know exactly how that will affect your feed. These personal algorithmic systems would be ours — an ambient layer on our explorations that would be truly personal, evolving with us as individuals, taking our values into account and adapting to us as well as providing a means for discovery. They would interface with recommending algorithms, keeping them in check and making sure we have priority agency in the content environments we explore.
“For many people personal data is abstract,” Koponen says. “Generally we don’t have a lot of awareness about how our data is being used and how it affects what we see. How could this data be powering experiences that are more in tune with who we are as individuals?”
An Experiment in Discovery
Kopenen’s app, Random, was his initial experiment in discovery, aimed to make the user’s subjective reality a starting point when recommending new topics and content. The New York Times described it as minimalist and almost toylike, probably because it’s simple and yet it inspires curiosity.
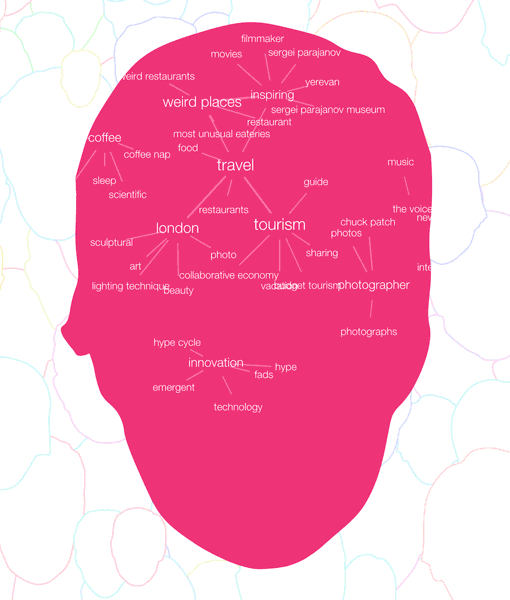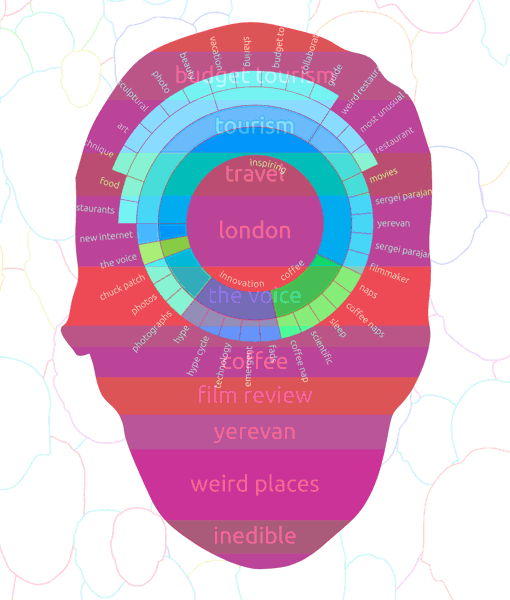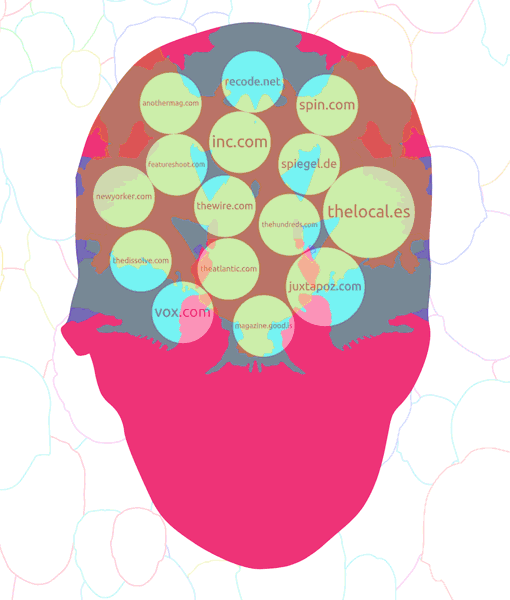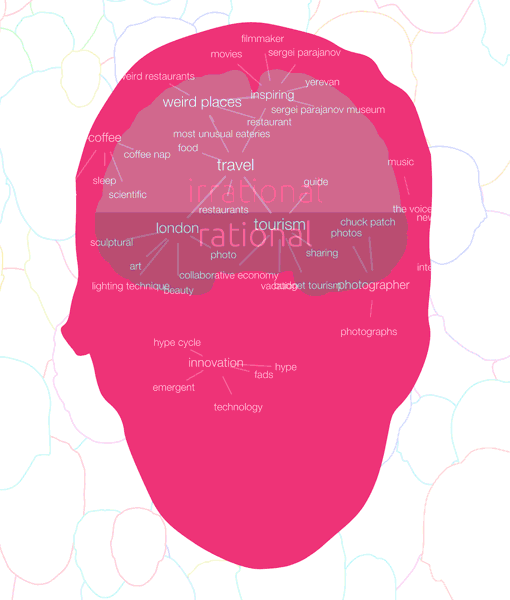
Random presents you with a screen tiled full of topics. When you click on a tile, it presents articles related to that topic. That helps the algorithm learn quickly. Each time you open it, your spread of topics is a little different. There are familiar subjects and some that make you go “hmm…”
“It doesn’t have a lot of utility yet,” Koponen says modestly, “but as a paradigm it could be made more comprehensive and approachable, to evolve into the kind of experience that gives you even more agency.” Like the algorithmic angel that hasn’t quite been invented yet. As the AI researchers in our podcast feature pointed out, discovery is an important part of the human experience, and so it should be an important part of what our technology enables. Currently, Random learns and adapts to your preferences, but also uses the network map of this data to enable surprise and discovery — to create a balance between relevance and serendipity.
Let’s say you’re into design, sushi, Apple, and travel. In Random, these are not categories per se, but points in a huge network graph that create your personal profile in the universe of the app. Nothing is truly random, of course. Surprise comes from:
1. Your personal choices
2. Expected correlations with other similar people
3. Trending topics
Where trends are concerned even though that particular connection may not be found in your profile, these topics are so popular at a given time that it’s likely that you’ll be interested in them. There was a bombing in Paris. Paris is something you’ve shown a lot of interest in, but you don’t always want to hear about bombings. Random takes that longer arc into account.
To take you beyond your current personal interests into new territory that won’t feel obtrusive, Random does an interesting pirouette, leapfrogging behind the scenes using subtle links within the content you consume. It looks for stepping stones. You might ask why you suddenly see an article on algae.
“Because of the interface and its underlying dynamics, it’s possible every now and then to bring in a wild card,” Koponen says. How is that different than anything Facebook or Twitter or Pinterest does? Because it’s just one of many choices that are presented to you, not an ad you have to look at.
You might like design, so somewhere back in the articles you read or that someone similar to you has read, there was a design article that was related to bioengineering and had to do with algae, and it somehow involved the design process. So now there’s just one suggestion for algae, and you don’t have to click on it unless you’re curious. There are many other choices. (Personally, I’d be curious enough just to know what the connection was).
What Does the Future Look Like?
Koponen is a humanist, so he’s always asking technology how it’s taking our personal values into account when it uses our personal data. Because what we consume feeds what we create, and all of this adaptive content universe will affect how human culture is curated — what our future looks like.
We want what we want, and even that’s hard enough to figure out, much less explain to a computer algorithm. That’s because most of those preferences bubble up from the subconscious, a far more complex network than anything we’ve ever built. We don’t want to look at the same things we’ve always seen before, but we don’t want to be insulted by stuff that’s too far out — jarring experiences that break our technology’s rapport with us.
We are creating our world even as we experience it through our unique perceptual filters. It shouldn’t come as a surprise. Machine learning — recommendation, discovery — is only reflecting that process and making it more obvious.
We created different media to ensure that we have access to the information that we consider valuable, meaningful. Something worth keeping. The key here, Koponen says, is that there will be technology creating information for us, technology that can be used as a mediator for curation. Culture is a repository of our connections, and it connects us to one another. But it also thrives on diversity. When machines are curating culture, we want them to understand that reality is subjective, but when it becomes too subjective it isolates us.
Personally, I want to understand how my culture, my network, is evolving — especially when machines are creating and making choices about the world that I see. Send me an angel already.


























